新しいサイトの方にブログを移管したため、技術探しは停止することになりました。このサイトのURLである https://blog.hiroppy.me は 301 で新しい方へリダイレクトされるため、過去の記事がリンク切れになることはありません。
しかし、はてブの数はURLで決定されるため、全ての記事が0という表記となります。
今まで多くの方に閲覧してもらい嬉しく思います。今後も新しいブログの方で会えたらと思います。
新しいサイトの方にブログを移管したため、技術探しは停止することになりました。このサイトのURLである https://blog.hiroppy.me は 301 で新しい方へリダイレクトされるため、過去の記事がリンク切れになることはありません。
しかし、はてブの数はURLで決定されるため、全ての記事が0という表記となります。
今まで多くの方に閲覧してもらい嬉しく思います。今後も新しいブログの方で会えたらと思います。
二回目の退職ブログとなってしまいましたが、6/30をもってメルカリを退職しました。
一回目の退職の後に、アイルランドに住みながらメルカリWebのリアーキテクチャに関する技術顧問として1年半ほど働いた後に日本に帰ったタイミングでお誘いを頂き、2019年の11月に二回目の正式な入社をしました。
入社後、リアーキテクチャとは異なりますが、メルカリwebの刷新プロダクトがはじまるということだったのでそちらに一年ぐらい開発に関わっていました。その後に、再度設立されたソウゾウの初期メンバーとして参加することとなりました。
チームメンバーとは2017年や技術顧問時代からの知り合いも多く、プライベートでも遊ぶような人たちばかりでした。数ヶ月後には、気づいたらチーム内の外国人の方の比率が多くなってきて共通言語はすべて英語となりました。この頃にメルカリのWebを0から刷新するプロダクトが始まり、一年近く開発に関わりました。
ソウゾウは、2021年1月28日に設立されたメルカリの子会社であり、メルカリShopsの開発を行う会社です。立ち上げ期から参加することとなり、メルカリのWebチームからソウゾウに出向しました。会社自体が0からだったので、何もかもが新鮮で、ベンチャー企業の立ち上げもこんな感じなのかなってふんわり感じました。この時期は自分の人生の中でも濃厚な経験があり、この会社に入って本当に良かったと今でも思っています。
ソウゾウはインフラからフロントエンドまで、一つのリポジトリで開発を行います。ここではフロントエンドやバックエンドみたいな職種分けがなく、なんでもできるシニアエンジニアが多い組織でした。技術スタックも良い選択だと思っています。
フロントエンドを最高に最適化したいのであれば、インフラからバックエンドまで全て関わらないと本当の最適化はできないという事は昔から思っていて、この開発体制は自分にフィットしていました。
メルカリShopsで行っているキャッシュ効率化の仕組みもこの開発体制でなければ、作れなかったでしょう。インフラ、バックエンドの仕組みを全て最初の設計段階からチームみんなで考えて整えることができたのは正解だと思います。
最初のリリースまでのメルカリShopsのフロントエンドは、自分がアーキテクチャ設計や大半のページの実装を行なっていました。途中から参加してくださったフロントエンドの方がいてくれたおかげで後半はかなり助けてもらい感謝しています。1人の開発だとなかなか相談できる人がいないので、途中から2人になってフロントエンドも安定してきたかと思います。 今では、フロントエンドエンジニアも4人いるので頼もしく、みんなに任せれる状態となりました。
開発組織もちゃんと整備され、リリース後にはEnablingチームで活動を行いました。色んな分野の方がいるチームなのは大変いい環境で、朝会ですら知らないことが多く学びを得る環境でした。(特に大学以来のML分野)
Enabling Team: 特定の技術/ビジネスドメインのスペシャリストで構成されるチーム。Stream-aligned teamのケイパビリティを埋める役割を持ち、Stream-aligned teamが自律的に活動して技術的解決法以外の課題にフォーカスできるようにすることをゴールとする
プロダクト開発はメンバーに任せて、フロントエンドをメインにDXの整備/改善やパフォーマンスチューニングを主な仕事としていました。フロントエンドが得意でない方でも開発できるように敷居をどれだけ下げれるかを考えていました。
ソウゾウの環境は自分にとって、ベストな環境でした。それでも次の会社を選んだ理由は複数あります。
自分をよく知っている方だと、あんな安定思考の人間がベンチャーに行くとは思ってなかったと思います。お誘いを頂いたときは正直ものすごく悩みましたが、人生も一度きりなのでプログラミング以外の分野に対しても挑戦してみたい思いがありました。toBもエンジニアリング組織も医療もすべてこれからの挑戦となります。
次の会社は、医療系の会社となります。
ここでは5, 6年近く付き合いがある@watilde、@leko をはじめ元McKinseyやAWS、お医者さんなどの医療系の方、このように本来会うことがなかった職種の方と働くこととなり、さらに今よりも多角な視野を持つことができるのではないかと思っています。自分は医療系の知識がほぼ0の状態でスタートするので、先述のようにこれからもプログラミング以外の学習の日々となり、それも1つの楽しみかなとも思います。
なにをやっている会社かについては、わちくんのブログがわかりやすいので引用させてもらいました。これに加えて、現在はNext.jsも利用しています。
プロダクトは、現状としては Node.js, Electron, TypeScript, React, NestJS, AWS あたりの技術スタックの上で、npm のようなエコシステムを持つ医療データに特化した ELT ツールのようなものを作っています。この領域では、dbt や Dataform など、様々な先駆者がいる理解をしていますが、ヘルスケア業界特有の非機能要件や要求されるユーザー体験に大きなギャップがありそうです。利用者の声を聞きながら、長期的に目指すビジョンの実現に合わせて形を変えながらチーム一丸となってプロダクトの開発をしていければと思います。
AWSを退職してYuimediに入社します – watilde's blog
今後は、食べログのWeb技術顧問に加えて、退職はしたものの7/1からソウゾウでも技術サポートとして微力ながらお手伝いを続けていきます。今後とも、食べログ/ソウゾウもよろしくお願いします。Yuimediをはじめ各社のお話が聞きたい場合はお気軽にカジュアル面談が可能となります。応募が多くなってしまったら調整してしまいますが、ご了承ください。
6/30 の六本木ヒルズです。
メルカリを退職しました、めっちゃ楽しかったです!ありがとうございました pic.twitter.com/jfVlqkqMI8
— 蝉丸ファン (@about_hiroppy) 2022年6月30日

30歳という節目でもあり、社会人になって、7年経ったのでせっかくなので振り返ろうかと思う。今日からformの枠で20代が使えなくなってしまったことは悲しい。
自分のキャリアはとても珍しいと思う。新卒でドワンゴに入り、後にメルカリへ行き、またドワンゴに行って今現在、メルカリ(souzoh)にいる。出戻りを歓迎してくれる会社は本当にいい会社だと思った。
そこでは、立ち上げフェーズでアーキテクチャの構築やベースを書く0 ->1をすることがほとんどでニコナレやN予備校、new メルカリWeb、メルカリShopsなどを作ったり、動画の最適化の研究をしたりしていた。あまり知られていないが、自分は画像処理の研究を3-4年間やっていたので、少しだけ画像や動画の最適化にも詳しかった。振り返って一番良かったことは、運が良かったのかどこのチームも仲のいい友人が多く出来て、あまり苦労しなかった。
技術面では、2015年の新卒の頃からreactを使って、2018年ぐらいまでredux, redux-sagaを使っていたが、2019年からはnext.js、apollo、graphql一択となり、今でもずっと使っている。メルカリShopsを作って以降、複数のプロジェクトでnestjsも使っているので今後のスタックとして候補に入りそう。
また、webにおける技術顧問も多くの会社でやらせてもらった。過去には、メルカリや現在でも続いている食べログ、他にも数社やっている。主にパフォーマンスチューニングのサポートやコードレビューをしたり設計相談でいい方向に導くのが大きな仕事であり、自分にとっても大きな発見があることが多い。
自分にとって、大きく人生が変わったものの一つだった。大学生の頃はOSSはあまりやってなかったが、ドワンゴの新卒で入ったときに同期に有名OSSをメンテナンスしている方がいて大きな刺激を受けた。2016年からはずっとNode.jsに関わり続けていて2017年にNode.jsのcore collraboratorとなった。その後に、webpackのコミッターとして、2019年以降、open collective経由で資金をもらいつつ活動してきた。
ただメンテナンスをする側になって、プログラミング以外で多くの問題を考えることが多くなった。レビュワー不足やそれに対してのコミッターを増やす採用方法など。自分たちはgoogle summer of codeをしてコミッターを増やしたり色々考えた気がする。
他にもOSSをやっててよかったのは、案外自分の名前が海外で知られてて、アイルランドに住んでたときにゲストでしゃべることになったり、いい経験となる機会を手に入れやすくなったことだと思った。
仕事とは、違った側面で多くの経験ができるOSSは今でも自分が薦めたい一つの楽しむ場所かなと思う。
今年の2/20に籍を入れて、落ち着いたと思いきやコロナの影響もあり、まだちゃんと両家で顔合わせをしたり等行っていないので案外バタバタしている。結婚式の準備も今真っ最中だが、コロナによる延期を避けたかったので今回は家族婚にした結果、まだゆったり出来ている部分もあるが。生活には大きな変化はないが、一人暮らしのときと比べて規則正しい生活となり、プライベートを大切にするようになった。
最近は、健康に気を使うようになって年齢を感じている。ただ、妻が料理の献立のバランスを取ってくれているおかげで前よりは健康だと思う。感謝しかない。
仕事でもパソコンみて、趣味でもずっとプログラミングをできる人生の先輩方はどういう眼球してるんだろうって思う。バトーの目にしたい。先生に言われて、寝る前に10分ぐらい目を温めて点眼して寝ることによって自分はある程度目の疲れを和らげている。
また、アイルランドの方に一度帰りたいのだが、戦争やコロナもありいつ行けばいいのやらって感じで悩みが残っている。
ありきたりではあるが、新しい挑戦をしつつ体は資本なので健康第一で生きていくことにしようと思う。もう少し私生活が落ち着いたらOSSにも戻ろうと思う。
最近、OSSやってないけど飽きたの?ってたまに聞かれることがある。飽きたというよりも、タイトル通り優先順位が変わってしまった。去年も健康診断を会社で受け、すべて大丈夫だったのだが、10月ぐらいから明らかな不調がわかっていて今も通院している状態である。
自分が通院しているのは眼科である。エンジニアという仕事柄、自分にとっては一番大切な箇所であり、返しづらい負債となっている。病状としては、眼圧が上がっていて、緑内障の疑いがあり(検査予定)、視力の低下。もともと視力はかなり悪いのに更に追い打ちがかかってしまった。特に眼圧なんてなかなか治らないしどうすればいいんだ感ある。目の手術はまだ気が進まない。毎日、目薬をうったりすることすら昔ならめんどくさく感じてしまうが、さすがにヤバさを感じたのか毎日できている。
中学の頃からゲームのようにプログラミングにハマって、数年前までは毎日13時間以上できてた。本当に今の目には感謝していてたくさん苦労をかけたと思う。近くをずっと見ているということは、ずっと目の筋肉が緊張していたのだから相当疲れているはずである。ただ、よく言われる「50分パソコンを見て、10分休憩で遠くを見る」 みたいなこと言われるが、自分にはそれが困難でコード書き始めると数時間続いてしまう。というか50分できりがよくプログラミング終わらない。。とりあえず目を温めなさいって言われているので、寝る前は15分程度温めていたりする。
今は、仕事以外ではあまりパソコン・スマホを見ないようにしている。し、将来もプライベートでパソコンを見る時間は減るだろう。「寝る前にスマホを見ない」とか一見簡単そうなこともできない人間なので、とりあえずインターネット依存自体を切り離したい。寝る前はスマホではなく、本を読もう。今後、目が使えなくなったら仕事でプログラミングすることすらできなくなる。
正直、プライベートでもコード書いてないと仕事で使ってない技術に対するキャッチアップできない不安も少しあるが、直近は体ともっと向き合おうと思う。コロナの様子見もつつ、山登りやキャンプが好きなので、もう少しアウトドアに注力してもいいのかなーって思ったりする。あとは、仕事の時間でどれだけ効率よく新しい知識や自分の知らない知識を吸収できるかが大切だなって感じた。
今年30歳になることもあり、健康の問題に直面し、復旧不可になる前に対処することにした。(手術もできるだけ回避したい) 既に29歳でガタが出ているので、人生100年時代生きれない。電脳化早く進んでほしい。
注意: これは公式見解ではない、ただ1メンバーの感想文です。
最近の大きなニュースとしては、webpackの主要メンバーの2人(Sokra, Alexander)は現在vercel雇われたことです。
🥳News: I have joined the awesome team at ▲ @Vercel
— Tobias Koppers (@wSokra) 2021年4月13日
While I'll continue to improve webpack, I'll also work on making Next.js even smoother...
Good news today, I have joined @vercel🌟
— Alexander Akait (@alexander_akait) 2021年12月29日
これによりメンテナンスの安定度が増したことは確かでしょう。現状の問題点はメンテナ不足です。webpackですら深刻です。 例えば今日、障害が発生しているmini-css-extract-pluginは一人で開発しているためレビュワーがいません。この2年ぐらいずっとこのような感じです。
アクティブなメンバーはごく数人であり、彼らがいなくなると途端に速度が低下されることでしょう。その中の二人が雇われたことは個人的には安心度があり良かったニュースです。しかしながら、安定はしても人数を増やさないとスケールしないので、どうOSSコミュニティを今後も広げていきメンテナンスできる人を増やすかは鍵だと思います。
さて、webpackがvercelの要望に引っ張られるかどうか?と聞かれることがありますが、それは自分にはわかりません。例えば、lazy compilationの実装も他のに比べてそこまで優先度は高くなかった記憶ですが、next.jsのonDemandEntriesをwebpack nativeに寄せるために優先度が上がったのかなと想像はしています。ただ、webpackはサービスというよりも、インフラであるため基本的に入る機能はユーザーに良い影響があるものばかりで、大きな心配はしてません。例として、現在cssに第一市民権を与える機能を追加していますが、これは誰に対してもいい影響を与えるものだと自信を持って言えます。
まだかなり実験的ですが、cssがwebpackで動くようになりました。css-loaderやmini-css-extract-pluginがこれにより不要となります / Release v5.66.0 · webpack/webpack https://t.co/abQDPRXiYH
— 蝉丸ファン (@about_hiroppy) 2022年1月12日
他にわかっている範囲では、vercelもswcのauthorを入れたことにより、話しているとwebpackにもacornからswcへ乗り換える可能性と優先度が上がってきていることを感じています。理由は明確で、next.jsも含めJS界隈で今注目されている開発速度向上のためです。今後、webpackからswc(bundle機能もまだまだ実験中ですが持っているため)へnext.js自体が完全に乗り換える可能性は否定できませんが、内部の人間ではないためそれは今後に注目しましょう。
ちなみにswcもwebpackのastを構築済みです。
https://github.com/swc-project/swc/tree/main/crates/swc_webpack_astgithub.com
他には、terser-webpack-plugin にswcとesbuildが入った点も同じ理由です。(もうパッケージ名と一致してない とは思っていますが)
唯一心配しているのは、今後のwebpackのopenCollectiveの運営に対してはどうなるのかなって思っています。webpackはOSSの中で大量のスポンサーがいることは有名です。少なくともv4までは、機能追加をスポンサー、ユーザーの投票で優先度を決めるということにしていました。
v4では以下の通り
しかし、現在のv5ではページ自体が機能していません。
スポンサーの意向が伝えられない状態でのopenCollectiveの運用は今後不明な要素となります。このスポンサーは果たしてvercelと比べてどれぐらい重みがあるのか? や voteページ機能してないけどどうするんだっけ みたいな問題が残っています。その反面、基本会社の仕事としてOSSをする場合は配当を受け取らないので、さらにプールに大きな余りができ、新しいメンテナを入れやすくなる点は良かったかなと思います。経験上、お金を払えばメンテナンスが続くわけではないですが、ないよりはあったほうがいいとは思います。いずれにせよ、このような不安はありつつ、これほど大きな資金を持つOSSで且つ会社に雇われる状況になったことがあるOSSは初だと思うので、今後に注目という事になりそうです。
まとめもなにもないですが、数年openCollectiveで運営していて特にコロナの影響で配当額が大幅に変わり、OSSフルタイムが厳しい状況もありました。それが会社に雇われて本当に良かったと思うのと同時に、今後のOSSコミュニティ運営について、注目していきたいと思います。
(なぜか2020年がない。。)
2021年は、ほぼ仕事の年でした。
1月にソウゾウという会社ができ、フロントエンドが得意なエンジニアが自分しかいない状況で初めてのベンチャーのような働き方をしました。なかなかできない体験だったので、良い経験となったと感じています。
今回のサービスは、webviewがターゲットだったため、パフォーマンスをずっと視野に入れる必要があり自分の得意な領域で仕事ができたのも大きかったです。多くの仕事だと、パフォーマンスの優先度は致命的にならない限り上がりづらい項目だと思っていて、それを容易に行えることが自分の一種のモチベーションとなっていました。
メルカリShopsのフロントエンド構成は以下を参照
フロントエンドが得意な人は、今では三人になって、みんな優秀で助かっていますが、今後も拡大させていくためにも来年は、発信に重きを置きたいと思います。
今の働き方も特殊で、自分はEnabling Teamというところに所属していて、主に開発者のインフラ整備やパフォーマンスチューニング等を行うのが仕事となります。プロダクトにあまり近くないこの働き方が自分にあっているかどうかはもう少し見極める必要があると思っていますが、今の所楽しくやっています。
また、今まで遠い存在だったCTOの名村さんとエンジニアとして同じチームで働けていることに感謝しています。エンジニアリング以外にも多くの学びがあり、昔よりは視野が少しは広くなったかなと感じます。
今年は仕事でほぼできていませんでした。たまにMTGとかに出る程度でチームチャンネルで会話したりするぐらい。
ただ、実は今、仕事で使っているchakra-uiのcoreチームには入っていて、コミットができる状態ではあるのでパフォーマンス周りをちゃんと整備していければと思っています。
いずれにせよ、2022年は仕事に振る割合をもっと減らすためOSSに戻れるようにしたいなと思っています。
嬉しかった話としては、一つの目標であった自分のリポジトリでスターが5000越したことです。
うぉぉぉぉ、初めて自分のリポジトリでスターが5000超えた、これめっちゃ嬉しいな🌟 一つの目標が達成されました! pic.twitter.com/VQWmVgpTor
— 蝉丸ファン (@about_hiroppy) 2021年10月28日
あとは、webpackも60000をついに越しました。
webpackのスターがついに60000になりました🌟 pic.twitter.com/i0Qy7u8e5c
— 蝉丸ファン (@about_hiroppy) 2021年12月17日
コロナの影響もあり、イベントの開催自体が少ない中、登壇する機会を提供してくれた多くの会社/組織に感謝します。
なにか全く違う分野の新しいことをしたいと思いつつ、健康を維持できるようにしたい。プログラミングよりも健康を優先にするようにする。
今回はgraphql-codegenを使い説明します。今回の例は、graphql-codegen以外でも発生する可能性がありますが自動生成系が一番顕著に影響がわかりやすいです。
graphql-codegenはよく、graphqlのスキーマからtypescriptの型定義/reactのhooks等を自動生成するのに使われますが、これはnext.jsと組み合わせた場合、少しトリッキーな部分があります。
www.graphql-code-generator.com
graphql-codegenはデフォルトでは1ファイルにすべて出力されますが、それに対しnext.jsは各ページをchunksとして吐くため何も考えずに実装すると、バンドルされるファイル量が膨大になる可能性があります。next.config.jsからwebpackの設定を上書きできますが、optimazationはかなり上書きしづらくそもそも上書きは基本避けるべきなのでその手法は取るべきではないです。
例えば、A, B, C query を例に以下を見てみましょう。
// generated/hooks.ts <- codegenによって作られたファイル import { gql } from '@apollo/client'; import * as Apollo from '@apollo/client'; export const ADocument = gql` query A { hero(episode: "JEDI") { name } droid(id: "2000") { name } } `; export function useAQuery(baseOptions?: Apollo.QueryHookOptions<AQuery, AQueryVariables>) { const options = {...defaultOptions, ...baseOptions} return Apollo.useQuery<AQuery, AQueryVariables>(ADocument, options); } export function useALazyQuery(baseOptions?: Apollo.LazyQueryHookOptions<AQuery, AQueryVariables>) { const options = {...defaultOptions, ...baseOptions} return Apollo.useLazyQuery<AQuery, AQueryVariables>(ADocument, options); } export const BDocument = gql` query B { hero(episode: "JEDI") { name } droid(id: "2000") { name } } `; export function useBQuery(baseOptions?: Apollo.QueryHookOptions<BQuery, BQueryVariables>) { const options = {...defaultOptions, ...baseOptions} return Apollo.useQuery<BQuery, BQueryVariables>(BDocument, options); } export function useBLazyQuery(baseOptions?: Apollo.LazyQueryHookOptions<BQuery, BQueryVariables>) { const options = {...defaultOptions, ...baseOptions} return Apollo.useLazyQuery<BQuery, BQueryVariables>(BDocument, options); } export const CDocument = gql` query C { hero(episode: "JEDI") { name } droid(id: "2000") { name } } `; export function useCQuery(baseOptions?: Apollo.QueryHookOptions<CQuery, CQueryVariables>) { const options = {...defaultOptions, ...baseOptions} return Apollo.useQuery<CQuery, CQueryVariables>(CDocument, options); } export function useCLazyQuery(baseOptions?: Apollo.LazyQueryHookOptions<CQuery, CQueryVariables>) { const options = {...defaultOptions, ...baseOptions} return Apollo.useLazyQuery<CQuery, CQueryVariables>(CDocument, options); }
上記のファイルをバンドルすると以下のように出力されます。これはwebpackが最適化を行うときに最初にtree shakingを行いすべてのJSファイルからimportされているもののみを実行関数(今回の例だとe.dの引数のオブジェクト内のYW等がトリガー)として列挙します。つまり、全ページで使われていないqueryはこのe.dの箇所には列挙されないこととなります。 ただし、使われてないqueryも定義自体はされることに注意してください。
// query: A, query: B のみを誰かが使いCは使ってない出力結果 7943: function (n, r, e) { "use strict"; e.d(r, { YW: function () { return b; }, $m: function () { return y; }, }); var t = e(6156), o = e(2465), u = e(7450), i = e(4569); function c() { var n = (0, o.Z)([ '\n query C {\n hero(episode: "JEDI") {\n name\n }\n droid(id: "2000") {\n name\n }\n}\n ', ]); return ( (c = function () { return n; }), n ); } function a() { var n = (0, o.Z)([ '\n query B {\n hero(episode: "JEDI") {\n name\n }\n droid(id: "2000") {\n name\n }\n}\n ', ]); return ( (a = function () { return n; }), n ); } function p() { var n = (0, o.Z)([ '\n query A {\n hero(episode: "JEDI") {\n name\n }\n droid(id: "2000") {\n name\n }\n}\n ', ]); return ( (p = function () { return n; }), n ); } var d = {}, // <-- default options O = (0, u.Ps)(p()); function b(n) { // <-- query: A var r = s(s({}, d), n); return i.a(O, r); } var v = (0, u.Ps)(a()); function y(n) { // <-- query: B var r = s(s({}, d), n); return i.a(v, r); } (0, u.Ps)(c()); // <-- query: Cは使われてないので変数化されない },
たとえどこのファイルからも使われていない場合でも、生成ファイルにquery(doc)があれば以下は出力に含まれます。使われている場合、上記のexportの部分に含まれるだけであとは同じです。これは最も無駄な部分であり、更にgqlが文字列だったりするのでファイルサイズを圧迫します。
function d() { var n = (0, u.Z)([ '\n query A {\n hero(episode: "JEDI") {\n name\n }\n droid(id: "2000") {\n name\n }\n}\n ', ]); return ( (d = function () { return n; }), n ); }
さて、問題点としてさっき言ったnext.jsは各ページのエンドポイントを持つ点に戻った場合、生成されたファイルがグローバルな共通化された状態で全てのエンドポイントにこのコード(chunkのnumberも一緒) を挿入します。
つまり以下のようなことが発生します。
これは、A, B, Cページに無駄なコードが必ず含まれているということです。 Aページでquery: Aを呼んだだけにも関わらず他のページで使われているqueryがチャンクに存在し、これはAからすると不要です。本来これは、生成ファイルを一つに結合するべきではなくその親チャンクと結合し生成ファイルは分解されるべきです。
以下のようなコードを書いた時点で../generated/hooksを参照しているすべてのチャンクはそれぞれに最適化後の../generated/hooksを持つことになります。
import { useAQuery } from '../generated/hooks'


2種類回避策があります。
自分の結論としては、2つ目しかないですが、最悪1つ目でもキャッシュの観点からすれば前の例よりはマシとなります。
appは特殊なファイルとして位置づけられ、すべてのファイルで呼び出されます。つまり、appでこの大規模な1ファイルを呼ぶと各エントリーポイントにある../generated/hooksが昇格し、_appの中に入り各エントリーポイントからいなくなります。各エントリーポイントからすると、appを読み込んだときに不要なqueryが大量に入ることは変わらないですが、appはどこでも使うファイルなので一回読み込めばそのコード自体がキャッシュが効くためネットワーク効率は上がります。
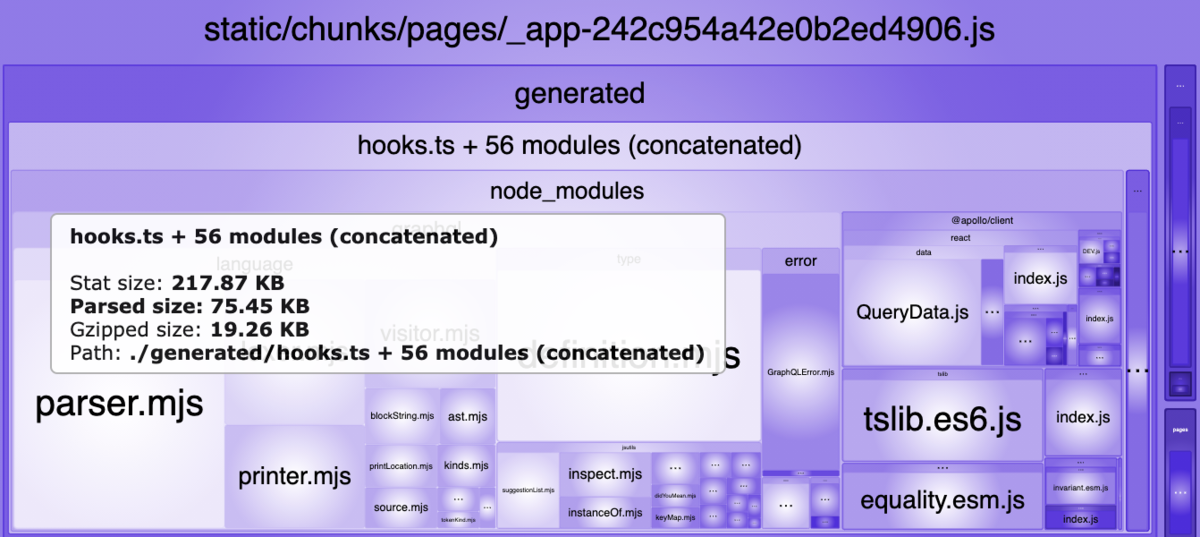

queryが増えていくと数千/万行になってエディタで見るのも大変になるので最適化以外の理由でも分けたほうがいいと思います。
幸いにも、graphql-codegenはnear-operation-fileを提供しているためそれを設定すれば完了です。
www.graphql-code-generator.com
# codegen.yml schema: src/schema.json documents: 'src/**/*.gql' generates: src/types.ts: # 型定義を逃がす - typescript src/: # hooksとかはこっち preset: near-operation-file presetConfig: baseTypesPath: types.ts # 上記のtypesをつなげる plugins: - typescript-operations - typescript-react-apollo
これを実行すると、各.gqlファイルの隣にtsのコードが生成されます。
documents/ ├── a.generated.ts ├── a.gql ├── b.generated.ts ├── b.gql ├── c.generated.ts └── c.gql
それを各エントリーポイントがimportすればそのファイルだけが読み込まれるためファイルサイズは最小限となり、不要なqueryの定義も入ることはありません。また完全に無駄がなくなりscope hoistingされるため結合され無駄な関数実行が減ります。

concatenatedと書かれている場合は、scope hoistingが効いてることがわかり、この例だと親のエントリーポイントとの結合がされています。
結論としてこのケースの場合、最善な最適化はファイルを適切に分割することです。
next.jsは、何も気にせずとも高品質なアプリケーションが作れますが、その分汎用的なものであるため必ずしも最適化が正しくなるとは限りません。ただバンドラの上書きはあまり良い方法ではないためチューニングしたい場合、上書き以外の方法を模索する必要があります。この例はgraphql-codegenを用いた話でしたが、それに限らず大規模なファイルを扱った場合に発生し、パフォーマンスに影響する可能性があるため注意が必要です。
(self.webpackChunk_N_E = self.webpackChunk_N_E || []).push([ [9], { 3242: function (n, r, e) { "use strict"; e.r(r), e.d(r, { default: function () { return y; }, }); var t = e(5893), o = e(6156), u = e(2465), i = e(7450), c = e(4569); function a() { var n = (0, u.Z)([ '\n query C {\n hero(episode: "JEDI") {\n name\n }\n droid(id: "2000") {\n name\n }\n}\n ', ]); return ( (a = function () { return n; }), n ); } function f() { var n = (0, u.Z)([ '\n query B {\n hero(episode: "JEDI") {\n name\n }\n droid(id: "2000") {\n name\n }\n}\n ', ]); return ( (f = function () { return n; }), n ); } function s(n, r) { var e = Object.keys(n); if (Object.getOwnPropertySymbols) { var t = Object.getOwnPropertySymbols(n); r && (t = t.filter(function (r) { return Object.getOwnPropertyDescriptor(n, r).enumerable; })), e.push.apply(e, t); } return e; } function p(n) { for (var r = 1; r < arguments.length; r++) { var e = null != arguments[r] ? arguments[r] : {}; r % 2 ? s(Object(e), !0).forEach(function (r) { (0, o.Z)(n, r, e[r]); }) : Object.getOwnPropertyDescriptors ? Object.defineProperties(n, Object.getOwnPropertyDescriptors(e)) : s(Object(e)).forEach(function (r) { Object.defineProperty( n, r, Object.getOwnPropertyDescriptor(e, r) ); }); } return n; } function d() { var n = (0, u.Z)([ '\n query A {\n hero(episode: "JEDI") {\n name\n }\n droid(id: "2000") {\n name\n }\n}\n ', ]); return ( (d = function () { return n; }), n ); } var O = {}, b = (0, i.Ps)(d()); (0, i.Ps)(f()); (0, i.Ps)(a()); var y = function () { (function (n) { var r = p(p({}, O), n); return c.a(b, r); })().data; return (0, t.jsx)("h1", { children: "top" }); }; }, 7878: function (n, r, e) { (window.__NEXT_P = window.__NEXT_P || []).push([ "/a", function () { return e(3242); }, ]); }, }, function (n) { n.O(0, [971, 774, 888, 179], function () { return (r = 7878), n((n.s = r)); var r; }); var r = n.O(); _N_E = r; }, ]);
_appにすべてのqueryが書かれている状態
(self.webpackChunk_N_E = self.webpackChunk_N_E || []).push([ [9], { 9217: function (n, u, t) { "use strict"; t.r(u); var r = t(5893), _ = t(7943); u.default = function () { (0, _.YW)().data; return (0, r.jsx)("h1", { children: "top" }); }; }, 7878: function (n, u, t) { (window.__NEXT_P = window.__NEXT_P || []).push([ "/a", function () { return t(9217); }, ]); }, }, function (n) { n.O(0, [774, 888, 179], function () { return (u = 7878), n((n.s = u)); var u; }); var u = n.O(); _N_E = u; }, ]);
(self.webpackChunk_N_E = self.webpackChunk_N_E || []).push([ [9], { 4462: function (n, r, e) { "use strict"; e.r(r), e.d(r, { default: function () { return b; }, }); var t = e(5893), o = e(6156), c = e(2465), u = e(7450), i = e(4569); function f(n, r) { var e = Object.keys(n); if (Object.getOwnPropertySymbols) { var t = Object.getOwnPropertySymbols(n); r && (t = t.filter(function (r) { return Object.getOwnPropertyDescriptor(n, r).enumerable; })), e.push.apply(e, t); } return e; } function a(n) { for (var r = 1; r < arguments.length; r++) { var e = null != arguments[r] ? arguments[r] : {}; r % 2 ? f(Object(e), !0).forEach(function (r) { (0, o.Z)(n, r, e[r]); }) : Object.getOwnPropertyDescriptors ? Object.defineProperties(n, Object.getOwnPropertyDescriptors(e)) : f(Object(e)).forEach(function (r) { Object.defineProperty( n, r, Object.getOwnPropertyDescriptor(e, r) ); }); } return n; } function p() { var n = (0, c.Z)([ '\n query A {\n hero(episode: "JEDI") {\n name\n }\n droid(id: "2000") {\n name\n }\n}\n ', ]); return ( (p = function () { return n; }), n ); } var s = {}, O = (0, u.Ps)(p()); var b = function () { (function (n) { var r = a(a({}, s), n); return i.a(O, r); })().data; return (0, t.jsx)("h1", { children: "top" }); }; }, 7878: function (n, r, e) { (window.__NEXT_P = window.__NEXT_P || []).push([ "/a", function () { return e(4462); }, ]); }, }, function (n) { n.O(0, [971, 774, 888, 179], function () { return (r = 7878), n((n.s = r)); var r; }); var r = n.O(); _N_E = r; }, ]);